


Ever wanted to build an advanced project to level up in building production-ready AI systems, and didn’t know where to start?
If so, Decoding ML’s philosophy is to learn by doing. No procrastination, no useless “research,” just jump straight into it and learn along the way. Suppose that’s how you like to learn, then we have the perfect free learning resource for you.
For the builders from the AI community, we created the Second Brain AI Assistant open-source course, where you will learn to architect and build a production-ready Notion-like AI assistant that talks to your digital resources.
→ An end-to-end AI system, from data collection to fine-tuning, deploying, and LLMOps.
The course is 100% free, with no hidden costs and no registration required. You just need Decoding ML’s GitHub and Substack articles.
This course will teach you the core concepts required to build LLM/AI apps while implementing a fun project: a Second-Brain AI assistant.
While following the articles and running the code yourself, you will gain valuable skills in all the AI engineering roles, such as building ML pipelines, LLMOps systems, and RAG agents.
Before digging into more technical details, let’s understand what a Second Brain AI Assistant is.
So, what is the Second Brain AI Assistant?
The Second Brain, a concept by Tiago Forte, is your personal knowledge base of notes, ideas, and resources. Our AI Assistant leverages this knowledge to answer questions, summarize documents, and provide insights.
Imagine asking your AI Assistant to recommend agent courses, list top PDF parsing tools, or summarize LLM optimization methods - all based on your research, without manually searching through notes.
What you'll do and learn:
While building your Second Brain AI Assistant, you will:
Build an agentic RAG system powered by your Second Brain
Design an end-to-end production-ready LLM & AI architecture: from data collection to deployment and observability
Apply LLMOps and software engineering best practices
Fine-tune and deploy LLMs
Evaluate agents
Use industry tools: OpenAI, Hugging Face, MongoDB, ZenML, Opik, Comet, Unsloth, and more
More details, such as who should join this course and the technical and hardware prerequisites, can be found in the GitHub repository.
After completing this course, you'll have access to your own Second Brain AI assistant, as seen in the video below:
Now, let’s move on to the fun part, where we zoom in on each lesson to understand better what it takes to build a Second Brain AI Assistant ↓↓↓
How to become a top 1% AI Engineer (Affiliate)
Did you know that becoming a top 1% AI engineer has less to do with mastering AI frameworks such as LangGraph and more with prioritizing your software engineering skills?
Here’s why:
AI systems don’t just rely on cool algorithms — they thrive on robust, scalable code. Without strong software engineering fundamentals, your AI/ML models will struggle in production.
To build a foundation for success, focus on these core skills:
Writing clean, modular code
Designing efficient cloud architectures
Mastering programming languages like Python and Rust
These software engineering skills are essential for creating AI/ML systems that work seamlessly in real-world scenarios.
So, how can you level up your skills effectively?
I recommend (and use myself) CodeCrafters.io, a platform tailored for developers who want to sharpen their software engineering expertise. It offers hands-on challenges where you build real-world tools from scratch, such as:
Docker
Git
Redis
Kafka
Shell
By working through these challenges, you’ll learn how to write production-grade code and gain hands-on experience in the technologies powering tomorrow's AI/ML systems.

If so, use my affiliate link to support us and get 40% off on CodeCrafters.io ↓
1. Build your Second Brain AI assistant
First, we will explore the system architecture of the Second Brain AI assistant, illustrated in the figure below. We will explain each component's role, what it is, what algorithms and tools we used, and, most importantly, why we used them.
By the end of this lesson, you will have a strong intuition of what it takes to architect an AI assistant for your Second Brain, such as a Notion-like AI assistant that allows you to chat with your notes and resources.

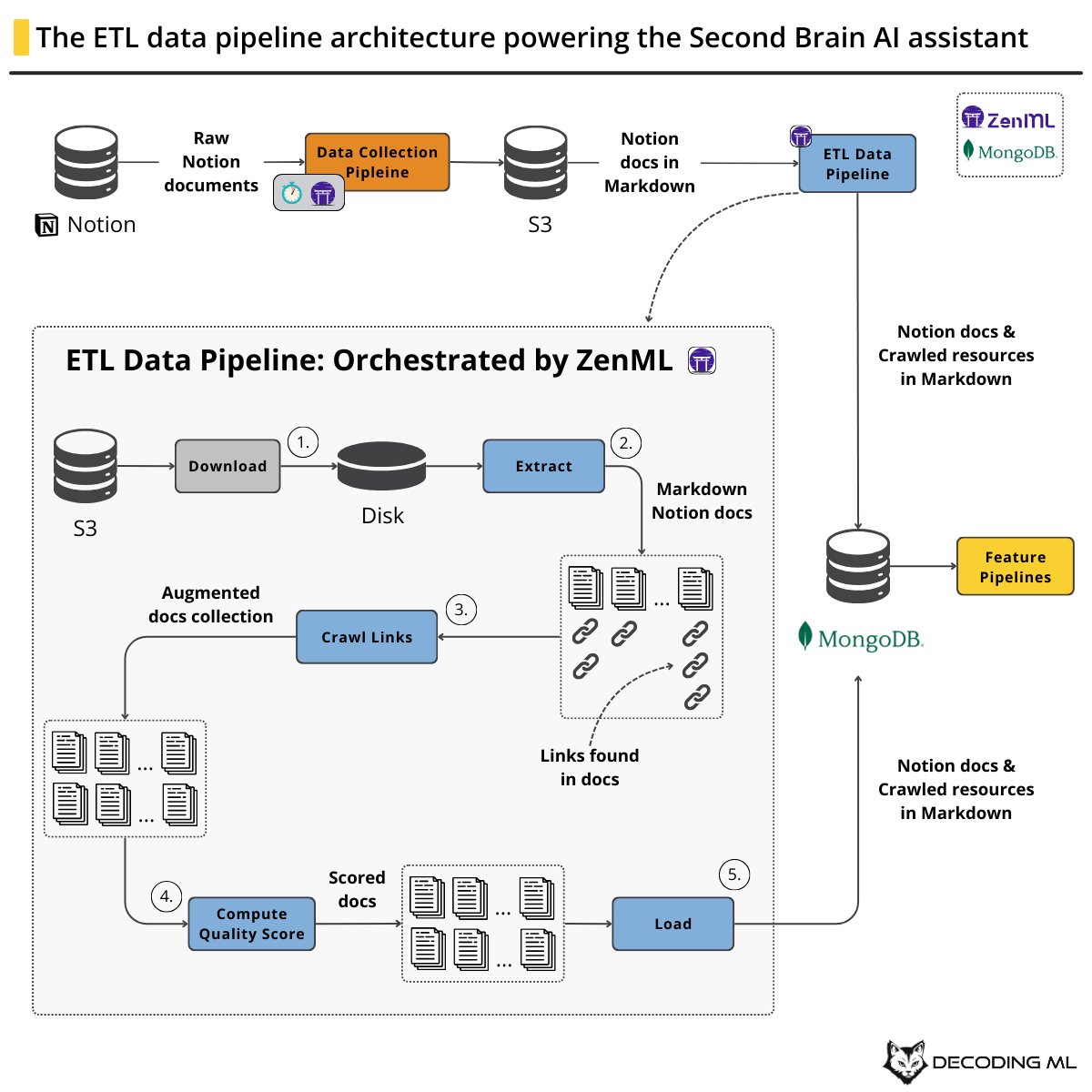
2. Data pipelines for AI assistants
Every data and AI system starts with data. If you don’t have data, you don’t have the raw material to work with. You can have the fanciest algorithms, but without data, they are still like a car without fuel.
Hence, this lesson will teach us to architect and build the data pipelines that fuel our Second Brain AI assistant, such as the Notion data collection and ETL data pipelines.
We will learn to manage data and ML pipelines using ZenML, an open-source MLOps framework.
We will collect data from Notion, but if you don’t want to hook up your Notion (or don’t have one), we prepared an easily downloadable dataset with our notes.
3. From noisy docs to fine-tuning datasets
In this lesson, we will learn to transform noisy documents collected from Notion and the Internet (through crawling) into a high-quality instruction dataset. This will allow us to fine-tune an LLM specialized in summarizing documents (an everyday use case for real-world projects).
Forget the ready-to-use datasets you see in online tutorials. In real-world projects, success comes from rolling up your sleeves and working through the messy process of preparing your own custom data.
Process that requires building a robust pipeline that collects, cleans, structures, and augments your data (as we started to explore in Lesson 2). This process ensures you have a high-quality and diverse set of samples to fine-tune your LLM (or any other AI model).

4. Playbook to fine-tune and deploy LLMs
Fine-tune an open-source LLM (Llama 3.1 8B) to specialize in summarizing documents. Deploy it as a real-time API endpoint.
Building your LLM and RAG application around APIs providers (e.g., OpenAI, Gemini) is a solid start to create a PoC or MVP quickly, but you will soon realize that:
Your API bill is skyrocketing.
You are vendor-locked in, and your application’s performance can degrade anytime (as you don’t have control over the LLMs).
You don’t have control over your data.
Thus, you need to find ways to optimize costs and gain more control over your models and data.
That’s why the next natural step is learning to use open-source LLMs (e.g., Llama, Qwen, or DeepSeek) to power your AI applications. Using swarms of open-source smaller language models (SLM) specialized in specific tasks is a solid strategy in reducing costs and gaining control over your AI system.
Thus, when using open-source models, you have two options:
Use them as they are and deploy them on your cloud provider of choice (e.g., AWS Bedrock, Hugging Face Dedicated Endpoints, Modal, on-prem)
If the models are too inaccurate for your use case, you must first fine-tune them on your specific task or domain (using Hugging Face’s TRL and Unsloth) and then deploy them.
In this lesson, we will assume that you need to do both. Therefore, using the summarization instruction dataset from Lesson 3, we will fine-tune a small language model (SLM) specialized in summarizing web documents collected from the internet and use Comet to track, measure, and compare the training experiments.

5. Build RAG pipelines that actually work
Context is the backbone of every intelligent AI assistant. Even the most advanced large language models (LLMs) can generate inaccurate or partial answers without the proper context, as it’s the fuel that powers meaningful, accurate, and valuable results.
That’s where Retrieval-Augmented Generation (RAG) steps in. By grounding responses in accurate, reliable data, RAG helps your assistant access external data and avoid hallucinations.
Most RAG problems are retrieval problems, which are the most challenging to solve. That’s why most advanced RAG techniques attack the retrieval step, providing better solutions to index and search data before sending the context to the LLM.
Simply put, the quality of the generated answer is the by-product of the quality and relevance of the provided context. It’s intuitive. If you pass the wrong data to the most powerful LLM, it will output trash.
Even if the LLM that you are using has huge context windows of 128k tokens or more, allowing you to ingest all your data into the prompt, you still need RAG, as:
Always sending huge prompts results in unsustainable costs and latencies.
The LLM will not know what to focus on. For example, if you pass an entire book inside the prompt, the LLM will use all the context to generate an answer. If you pass only the paragraphs you are interested in, you are 100% sure it will pick up the correct information.
The LLMs suffer from bias or might forget the necessary information from the context.
That’s why we dedicated an entire lesson to attacking various advanced RAG techniques, which will ultimately be unified under the RAG feature pipeline. This offline batch pipeline extracts data from MongoDB, processes it using advanced RAG techniques, and adds the data back to MongoDB (using text and vector indexes for search during RAG).

6. LLMOps for production agentic RAG
Implement the RAG agentic inference pipeline and an observation pipeline to monitor and evaluate the performance of the AI assistant.
Agents are the latest breakthrough in AI. For the first time in history, we give a machine complete control over its decisions without explicitly telling it. Agents do that through the LLM, the system's brain that interprets the queries and decides what to do next and through the tools that provide access to the external world, such as APIs and databases.
One of the agents' most popular use cases is Agentic RAG, in which agents access a tool that provides them with access to a vector database (or another type of database) to retrieve relevant context dynamically before generating an answer.
In this lesson, we will take the final step to glue everything together by adding an agentic layer on top of the vector index and an observability module on top of the agent to monitor and evaluate it. These elements will be part of our online inference pipelines, which will turn into the Second Brain AI assistant that the user interacts with, as seen in the demo below:
Thus, in this lesson, we will dive into the fundamentals of agentic RAG, exploring how agents powered by LLMs can go beyond traditional retrieval-based workflows to dynamically interact with multiple tools and external systems, such as vector databases.
Next, we will move to our observability pipeline, which evaluates the agents using techniques such as LLM-as-judges and heuristics to ensure they work correctly. We will monitor the prompt traces that power the agents using Opik, an open-source LLMOps tool, to help us debug and understand what happens under the hood.

How to take the course?
As an open-source course, it’s 100% free, with no hidden costs and no registration required.
The course is based on an open-source GitHub repository and articles that walk you through the fundamentals and the repository.
Thus, taking the course is super easy. You have to:
Navigate to the Second Brain AI Assistant GitHub repository and clone it.
Open the Substack lessons found in the repository’s GitHub docs.
Set up the code using the documentation from the repository.
Start going through the lessons and running the code.
The best part? We encourage you to reuse our code for your open-source projects! If you do, DM us on Substack, and we’ll share your project on our socials.
More details, such as who should join this course and the technical and hardware prerequisites, can be found in the GitHub repository.
Enjoy!
Whenever you’re ready, there are 3 ways we can help you:
Perks: Exclusive discounts on our recommended learning resources
(books, live courses, self-paced courses and learning platforms).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
Images
If not otherwise stated, all images are created by the author.
I found your articles and courses really helpful and insightful more than getting an official certification by this or that provider. But in order to make my skills and my cv the best fit for certain companies, we need also to get some. Can you suggest what certifications go more in this direction: that's to say AI Engineering?
Loved this roadmap it echoes exactly what I aim to foster both in the classroom and with clients:- building from fundamentals to firm, reliable systems.
In my AI and cybersecurity lectures, I use a similar phased approach helping students go from concept to constructing secure, adaptable pipelines. When consulting, that same roadmap becomes the backbone for evaluating real deployments, does this stand up to adversarial challenge or organizational complexity?
Your structure feels like a blueprint for turning curiosity into capability and for ensuring that AI engineering isn’t just theoretical but tightly woven into strategy, risk understanding, and live environments.
Would enjoy exchanging perspectives especially on connecting your roadmap to security-conscious deployments and resilient system thinking. Thanks for unpacking this so thoughtfully.