


The first lesson of the open-source course Building Your Second Brain AI Assistant Using Agents, LLMs and RAG — a free course that will teach you how to architect and build a personal AI research assistant that talks to your digital resources.
A journey where you will have the chance to learn to implement an LLM application using agents, advanced Retrieval-augmented generation (RAG), fine-tuning, LLMOps, and AI systems techniques.
Lessons:
Lesson 1: Build your Second Brain AI assistant
Lesson 2: Data pipelines for AI assistants
Lesson 3: From noisy docs to fine-tuning datasets
Lesson 4: Playbook to fine-tune and deploy LLMs
Lesson 5: Build RAG pipelines that actually work
Lesson 6: LLMOps for production agentic RAG
🔗 Learn more about the course and its outline.
Build your Second Brain AI assistant
Welcome to Lesson 1 of Decoding ML’s Building Your Second Brain AI Assistant Using Agents, LLMs and RAG open-source course, where you will learn to architect and build a production-ready Notion-like AI research assistant.
The best way to learn something new is by doing it. Thus, this course will teach you the core concepts required to build LLM/GenAI apps while implementing your Second-Brain AI assistant.
First, this lesson will present what you will build and learn throughout the course.
Next, we will explore the system architecture of the Second Brain AI assistant, illustrated in Figure 1. We will explain each component's role, what it is, what algorithms and tools we used, and, most importantly, why we used them.
By the end of this lesson, you will have a strong intuition of what it takes to architect an AI assistant for your Second Brain, such as a Notion-like AI assistant that allows you to chat with your notes and resources.

We will zoom in on each component in future lessons and present the theory and implementation behind each ML pipeline. Thus, by the end of this course, you will learn how to build your own AI assistant.
LLM systems have the same fundamental blocks. Hence, after going through our lessons, you will have the necessary knowledge to build your production LLM apps on your favorite use cases.
Let’s get started. Enjoy!
Podcast version of the lesson
Table of contents:
What are we going to build?
What are we going to learn?
Introducing the custom Notion data source
Exploring the flow of the data
Presenting the feature/training/inference (FTI) architecture
Architecting our Second Brain AI assistant
Offline vs. online ML pipelines
Running the code
1. What are we going to build?
As the first lesson of the open-source six-lesson course “Building Your Second Brain AI Assistant Using LLMs and RAG,” we must clearly define our ultimate goal, including what we will build and learn throughout the process.
Whether we're doing a course or implementing a real-world application, defining our end goal or target is critical.
In this course, we will show you how to build a custom AI assistant on top of your notes, lists or other resources that you usually store in apps such as Notion, Apple Notes, Google Keep, Evernote, Obsidian or similar applications.
The productivity geeks (such as myself) like to call the system that captures all your thoughts, tasks, meetings, events and notes “your Second Brain.” Usually, a Second Brain is more than just a note-taking app. It includes tools such as a calendar for meetings and cloud storage for, well…, storage.
For the sake of simplicity, we will narrow down our problem to building an AI assistant on top of our Notion custom data sources, imitating Notion’s AI features, as seen in Figure 2. Another similar example is NotebookLM, where you provide a set of sources, and the AI generates answers only based on them.

So… What will we build?
An AI assistant that generates answers solely based on our digital knowledge stored in our Second Brain, which, in our case, will be the data we store in Notion.
A Second Brain AI assistant is like having access to the collective wisdom of your own mind, extending your memory and quickly accessing your digital resources.
This is a relevant use case for avoiding hallucinations, as you limit the domain to your resources. You can easily control the generation and evaluation steps by conditioning the LLM to your resources.
As a fun (and relevant) example, we will use our list of filtered resources (which we keep in Notion) on AI and ML, such as GenAI, LLMs, RAG, MLOps, LLMOps and information retrieval.
Everyone has one of those, right?
The thing is that it gets hard to access exactly what you need when you need it.
Thus, we will show you how to hook a GenAI system on top of your research and resources to ask questions, retrieve relevant resources and synthesize information solely based on your research, which you already know is valuable and useful.
2. What are we going to learn?
Following Decoding ML’s mission, we will show you how to build an end-to-end AI system using the Second Brain AI Assistant as an example.
Thus, we will walk you through how to design such a system with production in mind.
Then, we will show you how to implement it, starting with collecting data from Notion, preprocessing and storing it, until using it to fine-tune LLMs and build an agentic RAG application.
As this is an educational project, we tried to avoid using frameworks such as LangChain and build everything from scratch. Doing so will help you develop your intuition, making using LLM frameworks a breeze.
Still, extensibility is a real pain when using LLM frameworks such as LangChain. Thus, real-world skills include extending these frameworks using object-oriented programming (OOP).
That’s why we used LangChain to load and retrieve data from a MongoDB vector database while showing you how to extend its components and add your app’s custom implementation.
Thus, in this course, we will cover the following concepts, algorithms and tools:
Architecting an AI system using the FTI architecture.
Using MLOps best practices such as data registries, model registries, and experiment trackers.
Crawling over 700 links and normalizing everything into Markdown using Crawl4AI.
Computing quality scores using LLMs.
Generating summarization datasets using distillation.
Fine-tuning a Llama model using Unsloth and Comet.
Deploying the Llama model as an inference endpoint to Hugging Face serverless Dedicated Endpoints.
Implement advanced RAG algorithms using contextual retrieval, hybrid search and MongoDB vector search.
Build an agent that uses multiple tools using Hugging Face’s smolagents framework.
Using LLMOps best practices such as prompt monitoring and RAG evaluation using Opik.
Integrate pipeline orchestration, artifact and metadata tracking using ZenML.
Manage the Python project using uv and ruff.
Apply software engineering best practices.
Excited?
Let’s start by exploring our custom Notion data source in more depth.
3. Introducing the custom Notion data source
You know what everyone says: “Every successful AI/ML project starts with understanding your data.”
Our use case is not different. It all starts with understanding our custom Notion data source.
If you are unfamiliar with Notion, you must know that it’s a fancier note-taking app that allows you to create notes, tasks, wikis and databases.
Figure 3 shows our eight Notion databases, which contain various resources on topics such as GenAI, information retrieval, MLOps and system design.
We use these notes, resources, and research to build AI and software products: “Yes, it’s the actual database we reference while building.”

Let’s dig into a specific database.
Figure 4 shows the “Generative AI” Notion database, which contains ~25 data entries on different topics in the space. The “Node” type contains high-level links, such as blogs, benchmarks, or awesome lists, while a “Leaf” contains super-specific resources or tools.
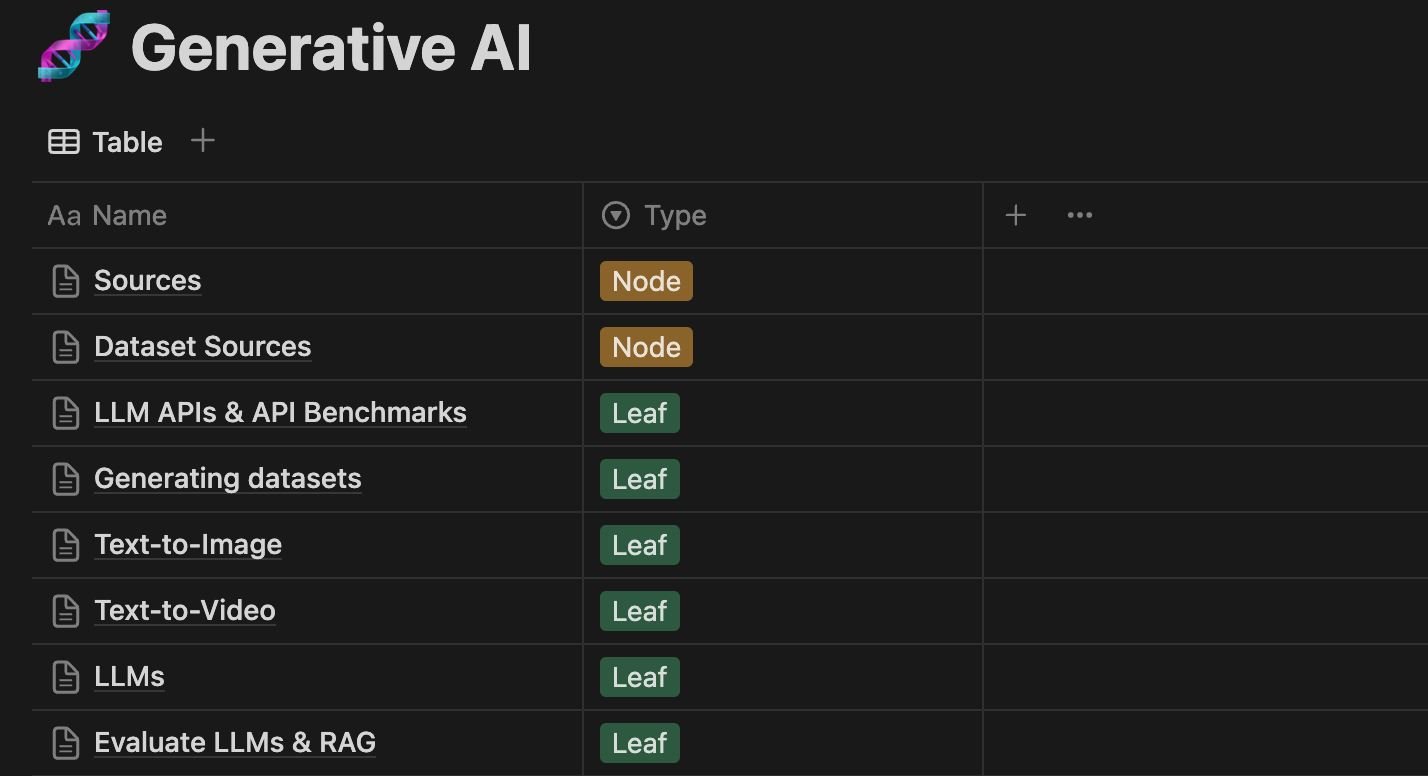
Let’s open a data entry.
As seen in Figure 5, we can see that a data entry contains:
Multiple “Notes” pages containing my thoughts on various topics.
Multiple “Toggle” elements contain links to various blogs, articles or tools.
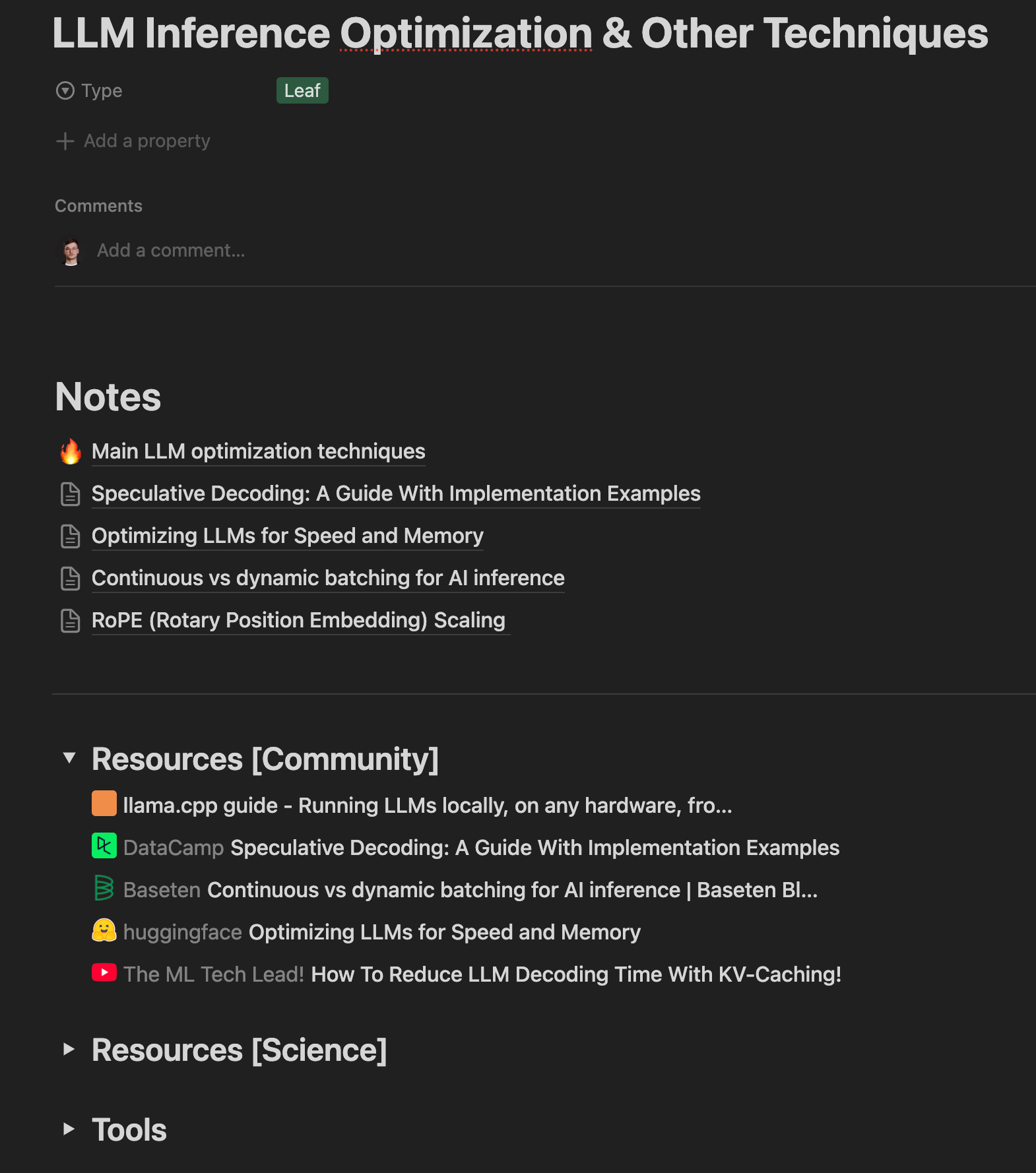
We integrated with Notion’s API and automatically downloaded and parsed all these documents in Markdown format.
The fun and interesting thing about this problem is that the data contains relevant links that must be crawled and further processed into Markdown. But, the catch is that the links are mixed with insightful notes we want to keep and feed into our system. Thus, we must find a way to differentiate between documents that contain only links for crawling and valuable documents by themselves.
A database entry will not always look like the one from Figure 5. The data is noisy and can have any form. The only rule is that it contains links, text, images, and attached documents (similar to a real-world use case).
We will stick to links and text for this course, but it can be extended to processing images and documents (a fun exercise for you).
For ease of use, we stored a snapshot of the Notion data from above in a public S3 bucket, which you can download without AWS credentials.
Thus, you don’t need to use Notion or hook your Notion to complete this course. But if you want to, you can, as we expose in the GitHub repository, a flexible pipeline that can load any Notion database.
The next step is to explore the data flow required to build your Second Brain AI assistant, from Notion to fine-tuning and RAG.
4. Exploring the flow of the data
The first step to understanding how our AI system looks is to understand its data flow, abstracting away other details such as tooling, infrastructure or algorithms.
Our goal is to collect data for Retrieval-Augmented Generation (RAG). Thus, we can feed our custom data as context to an LLM. We also need to collect data to fine-tune an open-source LLM (such as Llama 3.1 8B) to specialize in summarization (you will soon understand “why summarization”).
If you are not familiar with how a naive Retrieval Augmented Generation (RAG) system works, read more about it in Decoding ML:

As illustrated in Figure 6, let’s walk you through the flow and lifecycle of your data:
We collect raw Notion documents in Markdown format.
We crawl each link in the Notion documents and normalize them in Markdown.
We store a snapshot of the data in a document database.
For fine-tuning, we filter the documents more strictly to narrow the data to only high-quality samples.
We use the high-quality samples to distillate a summarization instruction dataset, which we store in a data registry.
Using the generated dataset, we fine-tune an open-source LLM, which we save in a model registry.
In parallel, we use a different filter threshold for RAG to narrow down the documents to medium to high-quality samples (for RAG, we can work with more noise).
We chunk, embed, plus other advanced RAG preprocessing steps to optimize the retrieval of the documents.
We load the embedded chunks and their metadata in a vector database.
Leveraging the vector database, we use semantic search to retrieve the top K most relevant chunks relative to a user query.
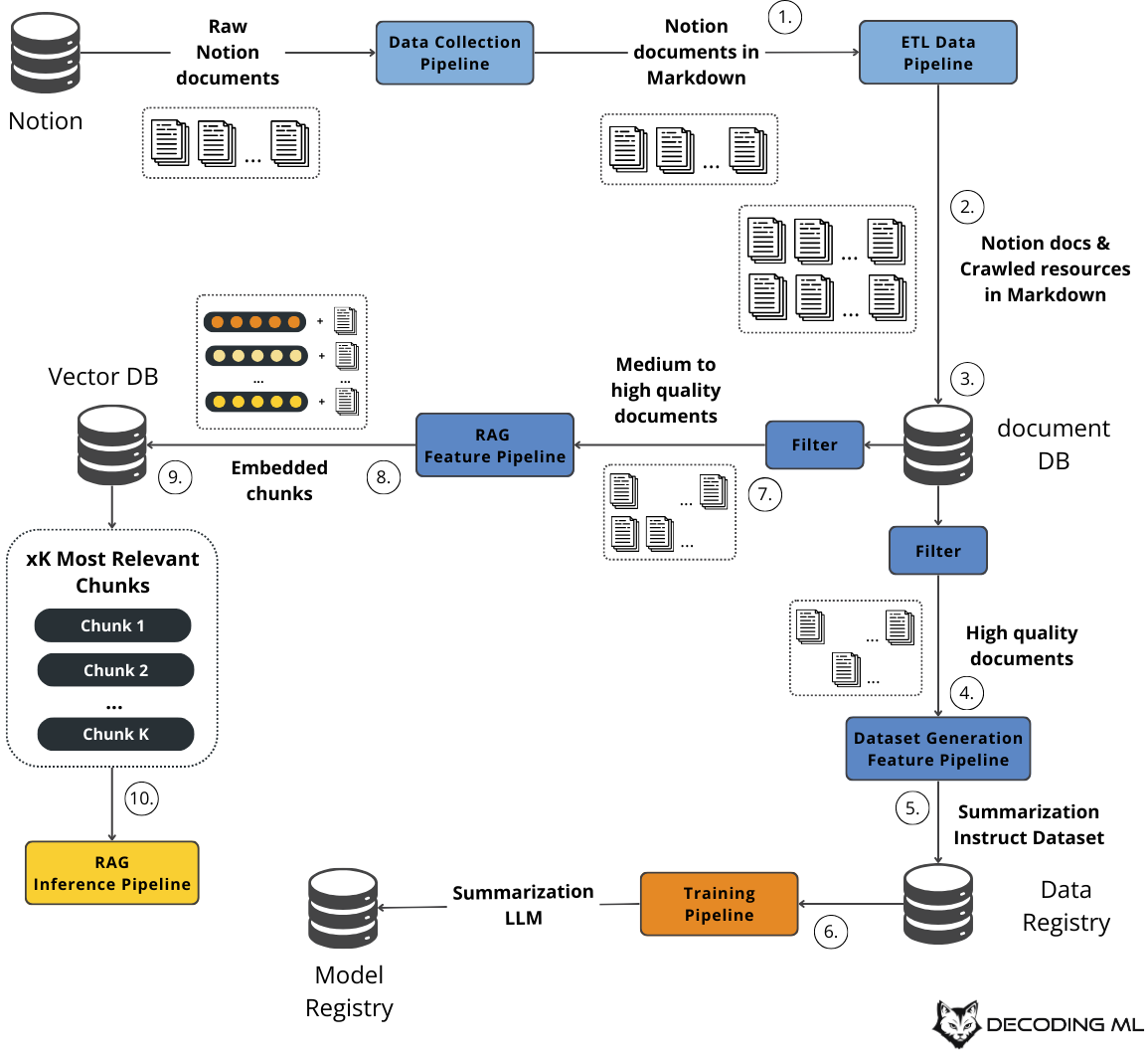
If something doesn’t make sense, don’t worry. Throughout the course, we will zoom in on each component and explain why and how we did everything.
Now that we understand how the data flows, let's quickly examine the feature/training/inference (FTI) design we will use to build our Notion AI assistant.
5. Presenting the feature/training/inference (FTI) architecture
The pattern suggests that any AI/ML system can be boiled down to these three pipelines: feature, training, and inference.
Jim Dowling, CEO and Co-Founder of Hopsworks, introduced the pattern to simplify building production ML systems.
The feature pipelines take raw data as input and output features and labels to train our model(s).
The training pipeline takes the features and labels from the feature stored as input and outputs our trained model(s).
The inference pipeline inputs the features and labels from the feature store and the trained model(s) from the model registry. Using these two components, we can make predictions in batch or real-time mode and serve them to the client.

Note that larger ML systems will have more than three pipelines. Thus, by convention, we name each pipeline based on its output artifact. That’s how we decide whether it’s a feature, training or inference pipeline.
To conclude, the most important thing you must remember about the FTI pipelines is their interface:
The feature pipeline takes in data and outputs features & labels saved to the feature store.
The training pipelines query the features store for features & labels and output a model to the model registry.
The inference pipeline uses the features from the feature store and the model from the model registry to make predictions.
It doesn’t matter how complex your ML system gets. These interfaces will remain the same.
There is a lot more to the FTI architecture. To learn more, consider reading the following article from Decoding ML:

6. Architecting our Second Brain AI assistant
Now that we have laid out all the foundations, such as understanding the data flow involved in building an AI assistant and the FTI architecture, let’s design our AI system.
As seen in Figure 8, we have 5 significant components that we have to understand:
The data pipelines
The feature pipelines
The training pipeline
The inference pipelines
The observability pipeline
You might wonder why we have five pipelines instead of three, as the FTI architecture suggests.
The data engineering team often owns the data pipeline, which prepares the data required to build AI systems.
Meanwhile, the observability pipeline is implemented on top of the FTI architecture to monitor and evaluate the system. Having eyes and ears all over your system is critical for success, especially in LLM systems, which are highly non-deterministic.
An ideal strategy is to implement an end-to-end workflow of your app quickly, plus the observability pipeline. Then, you use the metrics from the evaluation pipeline and logs from the prompt monitoring pipeline as clear signals on what works and what doesn’t.
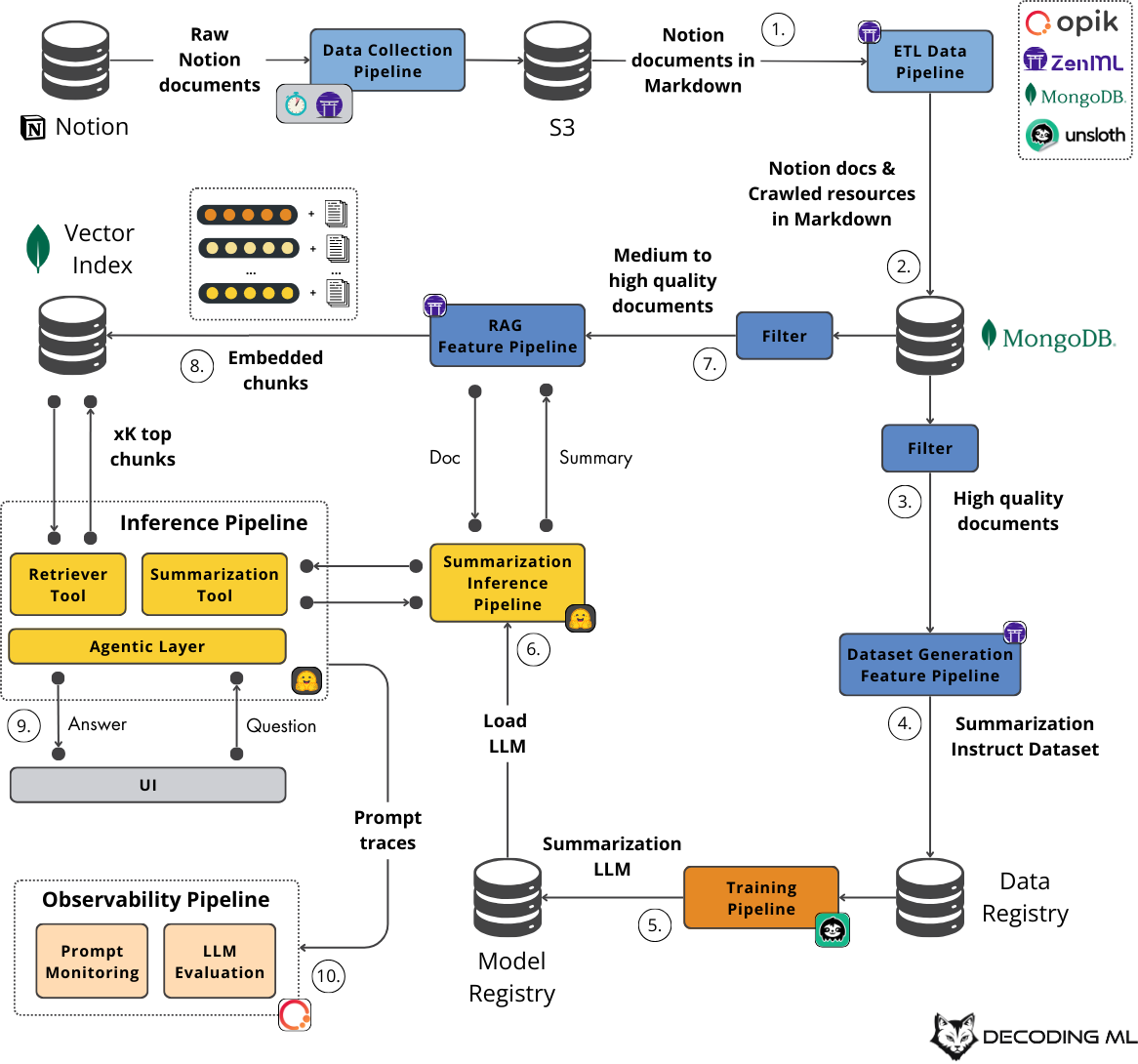
Let’s zoom in on each.
The data pipelines
As the name suggests, the data pipelines collect data from Notion, clean it, standardize it, and load it to a document database as our clean and normalized data snapshot before feeding it into the feature pipelines.
By storing the standardized and cleaned data in a document database, such as MongoDB, we collect the data once (as a backup), which we can use to experiment and build our AI system.
This is usually done with a data warehouse or lake in larger AI systems, but a document database is lighter and does the job for us.
The data pipeline is split into two significant components.
The data collection pipeline: It uses Notion’s API to retrieve the data programmatically, where each Notion data entry is standardized to Markdown format and saved as JSON along with necessary metadata. To decouple the data collection step from the rest of the system, we save everything to a public S3 bucket to avoid giving public access to our Notion workspace.
The ETL pipeline: It extracts the raw Notion documents from S3, finds all the embedded links within the documents, crawls them, and standardizes them into Markdown format. It also computes a quality score/document using LLMs. Ultimately, it saves all the documents and metadata into MongoDB.
The feature pipelines
The feature pipelines leverage the standardized and clean data from MongoDB for two things:
To populate a MongoDB vector index for doing RAG.
To generate a summarization instruct dataset for fine-tuning an LLM.
These are two standard feature pipelines you will see in the GenAI world.
Within the RAG feature pipeline, we will implement advanced pre-retrieval RAG techniques, such as Contextual Retrieval, proposed by Antrophic. To implement it, we will require a summarization LLM and hybrid search.
Ultimately, we chunk the documents, embed them, and load them into the MongoDB vector index.
For more theory on advanced RAG and how a naive RAG system can be optimized, you can read our article from Decoding ML:

Using APIs such as OpenAI for summarization can get costly (which we need for Contextual Retrieval), so we fine-tune a summarization open-source LLM. To do this, we require a custom summarization dataset.
Thus, we will leverage distillation techniques for the dataset generation pipeline to create a high-quality summarization instruction dataset based on our documents.
We will save the generated dataset to Hugging Face’s data registry. As an example, you can check our generated dataset: pauliusztin/second_brain_course_summarization_task
The training pipeline
The training pipeline reads the instruct dataset from the data registry and uses Unsloth to fine-tune a Llama 3.1 8B LLM. We use Comet to log the metrics and hyperparameters between multiple experiments, compare them, and pick the best one.
After deciding on the best model, we load it into Hugging Face’s model registry. As an example, you can check our fine-tuned LLM: pauliusztin/Meta-Llama-3.1-8B-Instruct-Second-Brain-Summarization
ZenML orchestrates and manages the data, feature, and training pipelines, helping us run the pipelines with a clearly defined structure and configuration. As illustrated in Figure 9, we can track the progress, status and history of each pipeline in a beautiful UI.

The inference pipelines
We have two inference pipelines.
The summarization inference pipeline, which contains only the fine-tuned LLM, is deployed as a real-time inference endpoint on Hugging Face’s Dedicated Endpoints serverless service.
The agentic inference pipeline is our AI assistant, which takes as input requests from a user and provides answers leveraging the data from the MongoDB vector database.
We implemented it using Hugging Face’s smolagents Python framework, which allows us to build agents without hiding too much of what is going on behind the scenes. We attached a retriever tool that interacts with the vector database and a summarization tool to help us synthesize answers.
We will also attach the agentic inference pipeline to a Gradio UI to completely simulate the experience of an AI assistant, as shown in Figure 10.

The observability pipeline
the last piece of the puzzle is the observability pipeline, which consists of two main components:
Prompt monitoring
LLM evaluation
For both, we will use Opik, which provides a beautiful dashboard for monitoring complex prompt traces, as seen in Figure 11.
It also provides a Python SDK to help us evaluate agentic and RAG applications, track the results and compare them (similar to experiment tracking, but for evaluating LLM applications).

7. Offline vs. online ML pipelines
One last architectural decision we have to highlight is the difference between the offline and online ML pipelines.
Offline pipelines are batch pipelines that run on a schedule or trigger. They usually take input data, process it, and save the output artifact in another type of storage. From there, other pipelines or clients can consume the artifact as they see fit.
Thus, in our AI system, the offline ML pipelines are the
Data collection pipeline
ETL data pipeline
RAG feature pipeline
Dataset generation feature pipeline
Training pipeline
These are all independent processes that can run one after the other or on different schedules. They don’t have to run in sequence, as they are entirely decoupled through various storages: a document database, a vector database, a data registry, or a model registry.
Because of their nature, we will orchestrate all the offline pipelines using ZenML, a popular ML orchestrator that allows us to schedule, trigger, configure, or deploy each pipeline.

On the other hand, we have online pipelines that directly interact with a client. In this setup, a client (e.g., a user or other software) requests a prediction in real or near real-time. Thus, the system has to be online 24/7, process the request, and return the answer.
In our use case, the online pipelines are the following:
Agentic inference pipeline
Summarization inference pipeline
Observability pipeline
Because of their request-answer nature, online pipelines do not need orchestration. Instead, they adopt a strategy similar to deploying RESTful APIs from the software engineering world.
It is critical to highlight that the offline and online pipelines are entirely different processes and often entirely different applications.
Seeing these LangChain PoCs, where the RAG ingestion, retrieval and generation are in the same Notebook, can be deceiving. You never (or almost never) want to ingest the data at query time; you want to do it offline. Thus, when the user asks a question, the vector database is already populated and ready for retrieval.
To clearly reflect this aspect, our codebase decoupled the offline and online pipelines into two different Python applications, as shown in Figure 13.

The last step is to say a few words about how you can run the code.
8. Running the code
This lesson was only an overview of what you will learn in the following five lessons. Thus, there is no specific code attached to this lesson.
However, if you want to test our code without going through the following lessons, we have provided end-to-end instructions on how to do so in our GitHub repository.
Thus, you can choose your learning journey: go through our lessons or directly try out the code.
Enjoy!
Conclusion
This lesson taught you what you will build and learn throughout the “Building Your Second Brain AI Assistant Using LLMs and RAG” open-source course.
In this lesson, we’ve laid out the foundations by presenting the data flow of the AI assistant and the FTI architecture.
Next, we’ve shown how to apply the FTI architecture on top of our data flow to architect a production-ready AI assistant.
Lesson 2 will focus on implementing the ETL data pipeline. While building it, we will learn how to use ZenML to orchestrate offline ML pipelines, crawl custom URLs, parse them to Markdown, and compute a quality score/document using LLMs.
💻 Explore all the lessons and the code in our freely available GitHub repository.
If you have questions or need clarification, feel free to ask. See you in the next session!
Whenever you’re ready, there are 3 ways we can help you:
Perks: Exclusive discounts on our recommended learning resources
(live courses, self-paced courses, learning platforms and books).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects, covering everything from system architecture to data collection and deployment.
References
Decodingml. (n.d.). GitHub - decodingml/second-brain-ai-assistant-course. GitHub. https://github.com/decodingml/second-brain-ai-assistant-course
Iusztin, P. (2024a, August 10). Building ML system using the FTI architecture. Decoding ML. https://decodingml.substack.com/p/building-ml-systems-the-right-way
Iusztin, P. (2024b, August 31). RAG Fundamentals first. Decoding ML. https://decodingml.substack.com/p/rag-fundamentals-first
Iusztin, P. (2025a, January 2). Advanced RAG Blueprint: Optimize LLM retrieval Systems. Decoding ML. https://decodingml.substack.com/p/your-rag-is-wrong-heres-how-to-fix
Sponsors
Thank our sponsors for supporting our work — this course is free because of them!





Images
If not otherwise stated, all images are created by the author.
I'll look this over. Would be interesting to develop this using my Obsidian notes and other sources rather than Notion.
Wow awesome Paul. Definitely follow the series. One more question: can i change notion to apple note?